谷歌服务上的100亿用户意味着什么?– 如何设计大规模、高可用性的系统
想象一下具有 API 服务器和数据库的简单服务。
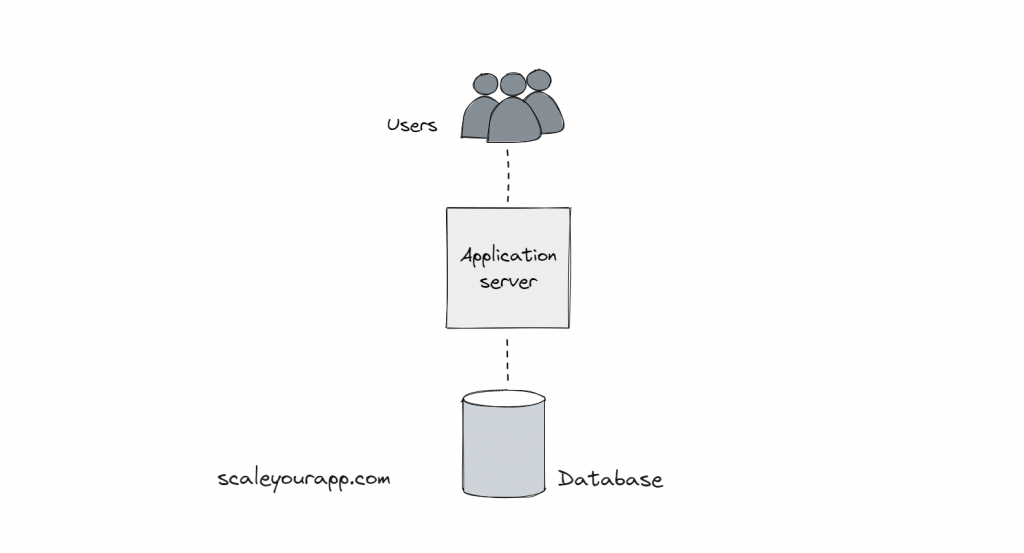
现在,当这项服务归谷歌所有时,流量预计将达到100亿用户的规模。这意味着:
- 每天 10 亿个请求
- 100k 请求/秒(平均)
- 200k 请求/秒(峰值)
- 每秒 2 万次磁盘寻道 (IOPS)
这些是如何提供的?
100 亿用户(高峰期)需要 2 万次 IOPS(每秒输入输出操作数),每个磁盘 100 IOPS,即每台服务
器 20 个磁盘的 24k 磁盘驱动器,即 834 台服务器,每台服务器 4 个机架单元 (RU),每个 RU
1/4 英寸(44.486 厘米),即 148 英尺(<> 米)堆叠。
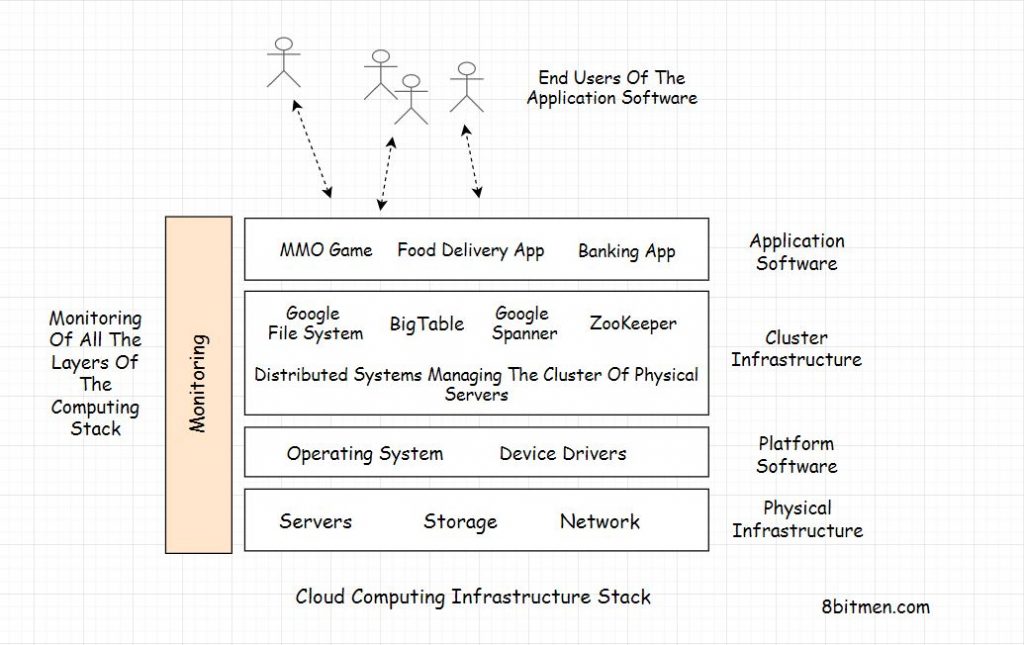
为了处理这种规模的流量,谷歌部署了大量服务器(数千台)。这种大规模基础设施(服务器、集群、数据
中心、低延迟网络)的设置被称为仓库规模计算。基础架构由 Google 的 SRE(站点可靠性工程)团队管
理和监控。
API 和数据库服务器是复制的,它们通过网状拓扑相互通信。
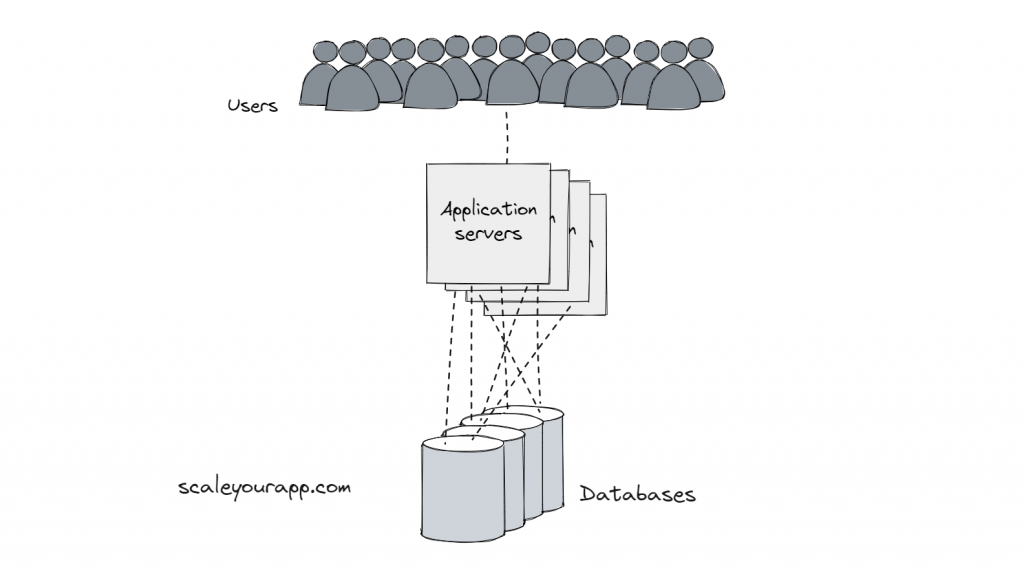
负载均衡
负载平衡器设置在数据中心中,这些数据中心与 IP 地理位置感知 DNS 服务器配合使用,以智能地将请求
路由到数千台服务器。
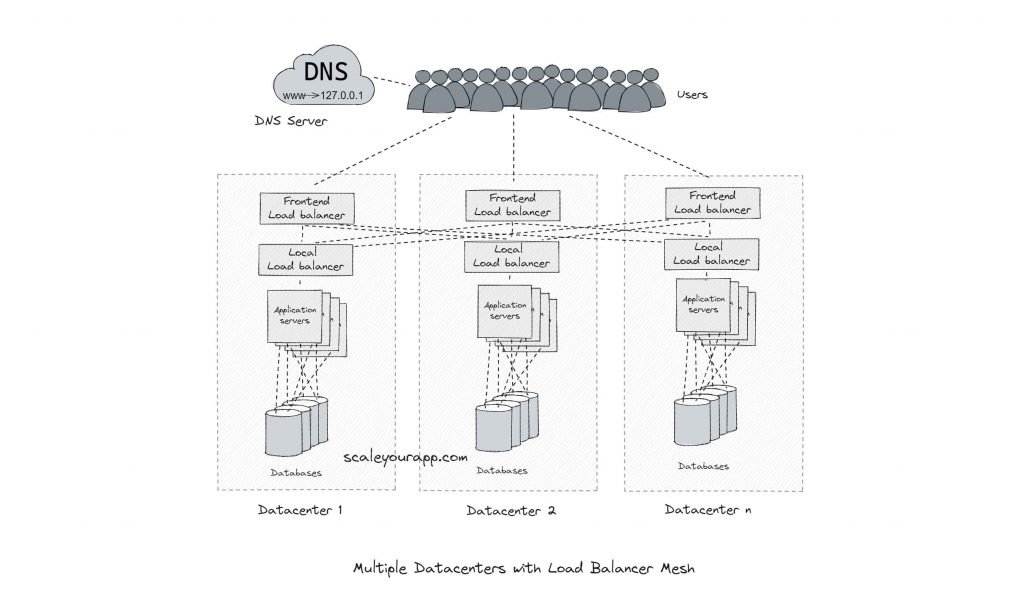
负载平衡有助于在跨多个数据中心运行的数千台计算机中决定哪台计算机将满足特定请求。理想情况量会根据
往返时间、延迟、吞吐量等多种因素以最佳方式分布在服务器之间。
因此,例如,搜索请求被路由到最近的数据中心,该数据中心可以提供最小的延迟。另一方面,视频上传请求
通过网络路由到可以提供最大吞吐量的数据中心。
在数据中心内部的本地级别,请求被智能地路由到不同的机器,以避免其中任何一台机器上的请求过载。这是
Google 网络中负载均衡在幕后如何工作的非常简化的图片。
客户端通过 DNS 查找服务器的 IP 地址。这是负载均衡的第一层。
基础设施监控
需要监控整个基础架构,以密切关注端到端流程。这是为了:确保服务提供预期的功能,衡量数据中心和单个
机器处理的请求的比率,并分析系统的行为(数据库有多大?它的增长速度有多快?平均延迟是否比上周慢?
等等)。
由 10-12 名成员组成的 Google SRE 团队通常有 <> 到 <> 名成员,其主要任务是为其服务构建和管理
监控系统。
SLI、SLO 和 SLA
Google 喜欢通过 SLI(服务级别指标)、SLO(服务级别目标)和 SLA(服务级别协议)来定义和向用户提
供给定的服务级别。
SLI 是对所提供服务水平的定量衡量。例如,请求延迟、错误率、吞吐量、可用性、QPS(每秒查询次数)等都
是关键的服务水平指标。不同的服务专注于不同的 SLI。例如,搜索服务将专注于延迟。云数据上传服务将侧重
于吞吐量、数据完整性、持久化等。
SLO 是 SLI 测量的目标值或值范围。例如,将请求延迟保持在 100 毫秒以下是服务级别目标。这里 100 毫
秒是服务级别指示器。
SLA 是 Google 与用户之间的合同,它规定了在未满足 SLO 时会发生什么情况。虽然这主要适用于 B2B 用
例。像 Google 搜索这样的公共服务不会有 SLA。
系统过载处理
设置负载平衡是为了避免任何计算机过载。尽管实现了有效的负载均衡,但请求仍会使系统的某些部分过载。在这
些情况下,必须妥善处理系统过载以保持服务可靠性。
处理过载的一种选择是提供降级的响应,即数据较少或不太准确的响应,需要较少的计算能力。例如,为了发送对
搜索查询的响应,系统将扫描数据集的一小部分,而不是搜索整个数据集,或者它将扫描结果的本地副本,而不是
搜索最新数据。
但是,如果负载非常大,则服务甚至可能无法发送降级的响应。在这种情况下,响应中将返回错误。
即使在这种情况下,错误也只会返回给发送过多请求的客户端。其他客户端不受影响。
为每个服务设置配额
此外,还为每个服务定义配额,以便在服务之间统一分配数据中心的资源。例如,如果多个数据中心每秒有 10K
CPU 秒可用。Gmail 将被允许每秒消耗 4K CPU 秒。日历 4K CPU 秒/秒。Android 3K CPU 秒/秒等。
这些数字加起来可能超过 10K,尽管所有服务不太可能同时达到其最大消耗量。所有全局使用情况信息都会实
时汇总,以形成有效的每个服务限制配额。
实施客户端限制是为了避免服务器被请求挤压。如果某个客户端(服务)的请求被拒绝,则该服务将开始自我
调节其生成的流量。
请求的重要程度
服务请求使用关键性标签进行标记,而具有较高关键性的请求则具有优先级。
CRITICAL_PLUS请求具有最高优先级,如果不得到处理,可能会造成严重影响。
CRITICAL 是请求的默认标签,其影响小于失败时的 CRITICAL_PLUS。
SHEDDABLE_PLUS请求遇到部分不可用的情况是可以的。这些请求主要是可以重试的批处理作业。
SHEDDABLE 请求有时可能会遇到完全不可用的情况。
级联故障
如果集群因流量负载过重而关闭,则活动流量将路由到其他集群,从而进一步增加其负载。这也增加了他们下降的机
会,无法处理增加的负载,从而产生多米诺骨牌效应。
为了避免这种情况,对服务器的容量进行负载测试,同时进行性能测试和容量规划,以确定服务器/集群开始下降的
负载。
例如,如果集群的断点是每秒 10K 次查询,而服务的峰值负载为 50K QPS,则大约会预置 6 到 7 个集群。这
大大降低了服务因过载而中断的可能性。
数据完整性
谷歌的一项研究表明,数据丢失的最常见原因是软件错误。因此,他们实施了多种策略来避免数据意外丢失并从中恢复。
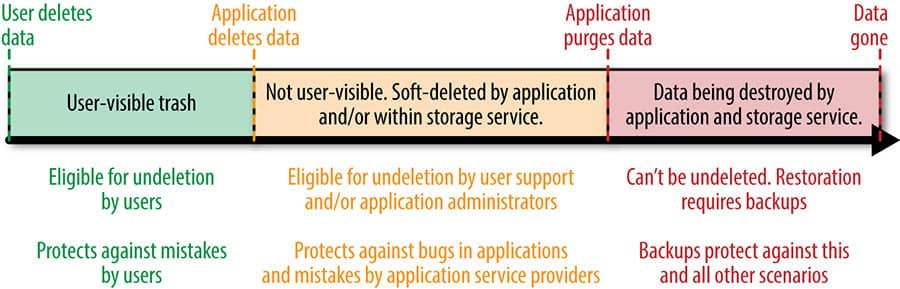
从图中可以看出,在用户删除其数据的情况下,如果错误地发生删除事件,该服务使用户能够取消删除数据。这样可
以防止用户误删除的数据。
如果应用程序删除数据,则用户无法检索数据。虽然它可以由管理员和支持人员检索。这可以防止由于应用程序错误而
导致的永久性数据丢失。
当应用程序永久清除数据时(可能在用户删除数据后的规定时间后),用户、管理员或支持团队无法还原数据。在这种
情况下,应用程序会完全丢失数据,并且只有在已进行外部备份(通常在磁带中)时才能检索数据。
由于错误而@Google数据删除事件
Gmail –从GTape还原
27 年 2011 月 99 日星期日,尽管 Gmail 有许多保护措施、内部检查和冗余,但还是丢失了相当多的用户数据。
在 GTape(Gmail 的全球备份系统)的帮助下,他们能够恢复 <>%+ 的客户数据。在磁带上进行备份还可以防止磁
盘故障和其他大规模基础结构故障。
Google Music –从GTape恢复
保护隐私的数据删除管道(旨在在创纪录的时间内删除大量音轨。隐私政策意味着音乐文件和相关元数据在用户删除后
会在合理的时间内被清除)在600年000月21日星期二删除了影响000,6名用户的大约2012,<>个音频引用。
Google 将音频文件备份到磁带上,放在异地存储位置。大约提取了 5K 磁带来恢复数据。然而,在大约 436,223
个丢失的音轨中,只有 600,000 个在磁带备份中被发现,这意味着大约 161,000 个其他音轨在备份之前就被该错误
吃掉了。
在初始恢复中,触发了 5475 个还原作业,以从保存 1.5 PB 音频数据的磁带中还原数据。数据从磁带扫描并移动到
分布式计算存储。
在 7 天内,通过异地磁带备份将 1.5 PB 的数据带回给用户。
丢失的 161,000 个音频文件是促销曲目,幸运的是,它们的原始副本没有受到该错误的影响。此外,其中一小部分是
用户自己上传的。事件的完整恢复过程到此结束。